Why can't error-tolerant parsers also be easy to write?
January 13, 2022 langdev parsing
Hello! In this post I’m going to talk about chumsky, a parser combinator
library that I wrote. It aims to be easy to use (even for beginners) yet also support elegantly recovering from syntax
errors, generating high-quality error messages, producing partial syntax trees when encountering errors, and providing
parser developers a lot of expressive control over parsing.
I’m going to talk about why I wrote it and discuss the things I think it does well, what I think could be improved, and what problems are still left to solve. In short: the good, the bad, and the ugly. Let’s get to it.
Modern parsers have demanding requirements
In particular…
They must be fast
A parser should be at least fast enough that its execution time is negligible compared to the rest of the compiler. This isn’t the 60s, we don’t have time to wait hours for our ALGOL 68 programs to compile.
They must produce good errors
It’s no longer good enough to emit a nebulous SyntaxError: invalid syntax (I’m looking at you, Python). Modern
development tools, including compilers, need to be accessible and productive. Users should not need to lower their
reasoning to the level of the compiler to understand what they did wrong. This means correctly and precisely
communicating problems with terminology users can intuit and, if possible, suggesting corrections.
They must be able to emit multiple errors at once
Modern software is complex and modern programming languages even more so. With rich static type systems and complex, heavyweight build systems, it’s suddenly important that compilers can produce errors that can be fixed in batches to maintain developer productivity. A parser should be able to encounter bad syntax, generate an error, and then continue onward to find more errors.
They must preserve information that they discover, even in the face of errors
Related to the previous point, but distinctly different; a parser should encounter a syntax error, recovery from it, and preserve the information it has discovered about the input to pass on to later compilation stages for further analysis. For a user, it doesn’t matter whether an error occurred during lexing, parsing, type-checking, or semantic analysis: they still want to see as many (legitimate) errors as they can without needing to run their build system again. That can only happen if the parser is error-tolerant and can still produce a partial syntax tree that can be passed forward.
Haven’t we solved parsing?
Yes!
… if your definition of a ‘parser’ is simply ‘a program that accepts valid syntax and does not accept invalid syntax’. But, as we’ve just discussed, modern parsers have far more demanding requirements.
Think about the number of times you invoke your compiler during a typical day of development. Now consider what proportion of these invocations result in a successful compilation.
I’d argue that the day job of a compiler is primarily to gracefully explain to the user what they did wrong and only incidentally to actually generate a binary on the weekends. Error reporting is, therefore, not simply an unusual deviation from the happy path: it is the happy path, and it is the one that we should prioritise thinking about when writing parsers.
Contrary to the established ivory tower of parser theory, this wider (and much more pragmatic) definition of parsing is very far from solved and we still have an enormous amount of work yet to do before our compilers are truly designed with human beings in mind.
Consider that most implementations of Python, JavaScript, and C# (to name a few) all fall to meet at least one of the criteria I listed above, being unable to either generate multiple errors at once, produce syntax trees from erroneus input for later analysis, or fail to produce errors that provide useful information for the user beyond pointing out that a syntax error was encountered.
Can we do better than this without devoting inordinate development effort toward hand-writing error-tolerant parsers?
Hand-written parsers
The best syntax errors out there are usually generated by hand-written parsers (i.e: parsers for which every parse rule is manually programmed by hand, often very explicitly, requiring a lot of time). Rust and Elm, both leaders in this space, use carefully crafted hand-written parsers, and it seems that many people believe that hand-written parsers are just inherently better at producing good error messages.
There’s no doubt that, on the far end of the spectrum, hand-written parsers definitely maximise control over the parsing process: but this is only a suitable tradeoff for languages that have a stable syntax and have had sufficient developer effort sunk into them that parsing each construct by hand is worth it.
For the rest of us: hobbyists, researchers, domain-specific languages (DSLs), etc. this approach is often a big obstacle to a language’s development and evolution. We’re stuck between a rock and a hard place: invest significant time into writing, testing, and maintaining a hand-written parser, or deal with complaints from users about the often atrocious errors generated by existing parser generators.
Parser combinators in the Rust ecosystem
Like most that jump into programming language development, my first parser was a shaky, unnecessarily explicit recursive descent parser written in Python. It scarcely worked, but what immediately captured my fascination was the manner in which top-down parsers that handle complex syntaxes are neatly composed of smaller, simpler parsers that call out to one-another, recursively, all the way down to trivially implementable ‘primitive’ parsers that do things like recognising specific tokens.
To me, it was truly beautiful and I set about trying to generalise the patterns I saw as much as possible. It didn’t take long to discover that I was essentially writing a parser combinator library, and that many already exist.
For those unaware, parser combinators are a technique for developing parsers that makes use of the hierarchical nature of top-down parsing. By combining primitive parsers together with generic ‘combinator’ parsers, parsers for more complex syntaxes can be created. The result of each combination of parsers is itself a valid parser for a context-free subset of the wider syntax. Parsers written with combinators are usually written in a declarative style that more closely resembles the underlying syntax structure, making working with them significantly less arduous.
Excited by the prospect that others had taken this journey before me, I set out to find the best parser combinator
library that I could, but was sourly disappointed by what I found. While there are several parser combinator libraries
out there that fulfil some subset of the criteria I mentioned at the top of this blog post, only one
(megaparsec) appears to meet all criteria and, predictably, it’s
written in Haskell.
In the Rust ecosystem, we have:
These are great libraries, but they’re all geared towards parsing valid input and don’t do much to accomodate elegantly handling invalid input, only producing either a syntax tree or a single error message. This was not satisfactory to me: as we previously established, error handling cannot be considered an afterthought: parsing invalid input is the default mode of operation of a compiler’s parser.
(There have been attempts to coerce nom into performing error
recovery, but doing so seems to break out of the intended use patterns of the library considerably)
I was quite disturbed by this ‘gap in the market’, so I set out to try to write my own library that resolved these issues. This is usually a dangerous habit of mine: many a weekend has been wasted trying to solve a problem better than existing alternatives only to find that that the problem in question is actually just really hard.
I’d made a few attempts at writing parser combinator libraries before, so I had some practice under my belt. However, my past attempts were nothing special: like the aforementioned libraries, they didn’t cater to syntax errors particularly well. I really wanted to push past these limitations and make error recovery a first-class use-case of the library.
Enter chumsky
One weekend (and 6 months 😫: it turns out that the problem is really hard!) later, I’m happy to report that I have
something to show for my efforts: a Rust parser combinator library named chumsky that fits all of the criteria I
mentioned at the beginning of the post.
The good
Here’s an example of the errors generated by my own language, Tao, when given the following input containing numerous syntax errors.
def hello = if True
then (4 + £])
else 5!
Tao’s compiler uses chumsky for both its
lexer and
its parser: as a
result, it’s able to report many lexer, parser, and type errors at once. It’s been a useful
dog food project to accompany the development of chumsky!
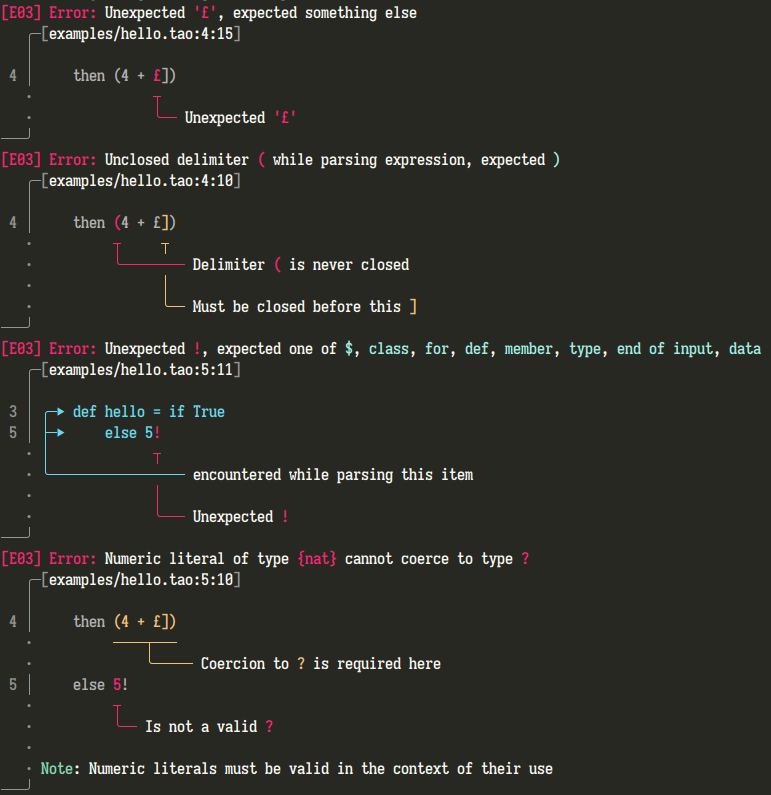
I don’t want to pretend for a moment that these error messages are perfect: they are not. However, a few points stand out:
-
The errors are of significantly higher quality than those normally produced by parsers written with parser combinator libraries.
-
I have considerable control over the error generation process: I can add context-specific details to errors inline within the parser’s code, and fine-tune the error recovery process to fit the language’s syntax. For example, check out the following error that exists specifically for Tao’s unusual pattern match syntax when giving the following input.
def hello = match Just 5 in | Some x => 3 # Missing line here: \ None => 0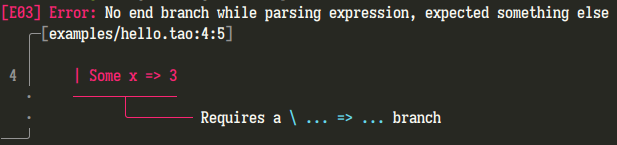
The code required to generate this error is just a handful of trivial lines.
Despite this fact, the logic that generates errors, records errors, performs recovery, and selects between error sets on different parse branches is all hidden behind the declarative parser API.
-
Access to the source spans of parsed elements is automatic, allowing the creation of errors messages that refer back to precise locations in the original source code. Support for spans is built into
chumskyand no additional boilerplate is required to support them. -
None of these features come with any significant syntax overhead, nor implementation complexity. The code required to perform error recovery in this JSON parser is just 3 lines, for example.
-
The whole library feels very ergonomic to write parsers with and scales without much difficulty from trivial syntaxes all the way up to rather complex ones indeed (as demonstrated by Tao).
At least, I feel that this is a refutation of the idea that parsers written with combinators are insufficient to produce high-quality syntax errors.
I plan to maintain chumsky for the forseeable future, so feel free to
give it a spin!
The bad
Note: this information is now out of date. chumsky has improved substantially of late and many of the points below are either no longer valid or have reasonable workarounds.
Although writing parsers with chumsky is ergonomic, there are some drawbacks.
-
As with all recursive descent PEG parsers,
chumskydeals with ambiguity by outright ignoring it: the first depth-first pattern that parses is considered the canonical output of the parser. This means that you’ll still need to run your syntax through some other system checker to ensure that it does not contain ambiguity. -
Error recovery comes with some overhead: I’ve made an attempt to keep things performant, and there’s definitely still more to be done in this space, but the logic required to properly resolve diverging parse paths and choose the most sensible error sets is a little contrived and requires more allocation than is perhaps desirable. For this reason, I would not recommend using
chumskyfor applications that don’t require error recovery (parsing machine-generated data, for example). -
As with any recursive descent PEG parser,
chumskyis designed for context-free languages only. While it is possible to parse context-sensitive syntaxes such as Python’s semantic whitespace, it must be done by first pre-processing the source code into a more traditional brace-delimited token stream in the compiler’s lexer manually. -
Left recursion is still a problem, as with all recursive descent parsers. It is relatively simple to restate left-recursive rules as right-recursive ones however, and I’m looking into strategies for handling these cases by automatically detecting and negating left recursion to allow such patterns to be parsed.
The ugly
There are a number of things I’d like to improve about chumsky:
-
Support for zero-copy parsing
-
Reducing the overhead of error recovery
-
Support parsing recursive token types (like Rust’s token trees)
-
Better handling of ambiguity between patterns that both perform error recovery (see here for more information)
Note: chumsky has improved substantially of late and almost all of these things have now been implemented.
Conclusion
After my time developing chumsky, I’m convinced that it’s not only possible, but also practical, to write high-quality
parsers that perform reliable error recovery using more declarative approaches to parser development, if we break out of
the existing view that parsers are just programs that accept valid input and reject invalid input.
I’m hopeful that chumsky can become a useful tool for hobbyist programming language developers looking to iterate
quickly on syntax while retaining good error generation.
I’m planning to write another blog post that explains chumsky’s internals in more detail at some point, but I’ll leave
things here for now to avoid to avoid this post becoming too long.
Thanks to Domenic Quir for feedback and review